Тема: OLAP-технология
3. История создания OLAP-технологии
5. Типовая
архитектура систем многомерного интеллектуального анализа
1. Bведение
В последнее время много написано про OLAP. Можно сказать,
что наблюдается некоторый бум вокруг этих технологий. Правда, для нас этот бум
несколько запоздал, но связано это, конечно, с общей ситуацией в стране.
Информационные системы масштаба предприятия, как правило,
содержат приложения, предназначенные для комплексного многомерного анализа
данных, их динамики, тенденций и т.п. Такой анализ в конечном итоге призван
содействовать принятию решений. Нередко эти системы так и называются – системы
поддержки принятия решений.
Системы поддержки принятия решений обычно обладают
средствами предоставления пользователю агрегатных данных для различных выборок
из исходного набора в удобном для восприятия и анализа виде. Как правило, такие
агрегатные функции образуют многомерный (и, следовательно, нереляционный) набор
данных (нередко называемый гиперкубом или метакубом), оси которого содержат
параметры, а ячейки – зависящие от них агрегатные данные – причем
храниться такие данные могут и в реляционных таблицах, но в данном случае мы
говорим о логической организации данных, а не о физической реализации их
хранения). Вдоль каждой оси данные могут быть организованы в виде иерархии,
представляющей различные уровни их детализации. Благодаря такой модели данных
пользователи могут формулировать сложные запросы, генерировать отчеты, получать
подмножества данных.
Технология комплексного многомерного анализа данных
получила название OLAP (On-Line Analytical Processing).
OLAP – это ключевой компонент организации хранилищ данных.
Концепция OLAP была описана в 1993 году Эдгаром Коддом,
известным исследователем баз данных и автором реляционной модели данных (см. E.F. Codd, S.B. Codd,
and C.T.Salley, Providing OLAP (on-line analytical processing) to
user-analysts: An IT mandate. Technical
report, 1993).
В 1995 году на основе требований, изложенных Коддом, был
сформулирован так называемый тест FASMI (Fast Analysis of Shared
Multidimensional Information – быстрый анализ разделяемой многомерной
информации), включающий следующие требования к приложениям для многомерного
анализа:
·
предоставление
пользователю результатов анализа за приемлемое время (обычно не более 5 с),
пусть даже ценой менее детального анализа;
·
возможность
осуществления любого логического и статистического анализа, характерного для
данного приложения, и его сохранения в доступном для конечного пользователя
виде;
·
многопользовательский
доступ к данным с поддержкой соответствующих механизмов блокировок и средств
авторизованного доступа;
·
многомерное
концептуальное представление данных, включая полную поддержку для иерархий и
множественных иерархий (это – ключевое требование OLAP);
·
возможность
обращаться к любой нужной информации независимо от ее объема и места хранения.
Следует отметить, что OLAP-функциональность может быть реализована различными способами, начиная с простейших средств анализа данных в офисных приложениях и заканчивая распределенными аналитическими системами, основанными на серверных продуктах. Пользователи могут легко рассматривать данные на многомерной структуре в применении к собственным задачам.
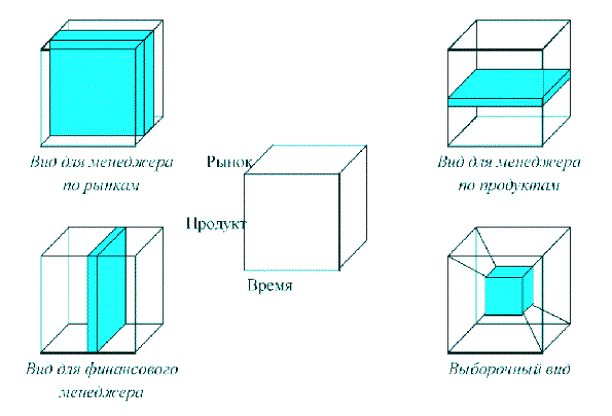
2. Что такое
OLAP
OLAP – аббревиатура от английского On-Line Analytical Processing
– это название не конкретного продукта, а целой технологии. По-русски удобнее
всего называть OLAP оперативной аналитической обработкой. Хотя в некоторых
изданиях аналитическую обработку называют и онлайновой, и интерактивной, однако
прилагательное “оперативная” как нельзя более точно отражает смысл технологии
OLAP.
Разработка руководителем решений по управлению попадает в
разряд областей наиболее сложно поддающихся автоматизации. Однако сегодня
имеется возможность оказать помощь управленцу в разработке решений и, самое
главное, значительно ускорить сам процесс разработки решений, их отбора и
принятия. Для этого можно использовать OLAP.
Рассмотрим, как обычно происходит процесс разработки
решений.
Исторически сложилось так, что решения по автоматизации
оперативной деятельности наиболее развиты. Речь идет о системах транзакционной обработки
данных (OLTP), проще называемых оперативными системами. Эти системы
обеспечивают регистрацию некоторых фактов, их непродолжительное хранение и
сохранение в архивах. Основу таких систем обеспечивают системы управления
реляционными базами данных (РСУБД). Традиционным подходом являются попытки
использовать уже построенные оперативные системы для поддержки принятия
решений. Обычно пытаются строить развитую систему запросов к оперативной
системе и использовать полученные после интерпретации отчеты непосредственно
для поддержки решений. Отчеты могут строиться на заказной базе, т.е.
руководитель запрашивает отчет, и на регулярной, когда отчеты строятся по
достижении некоторых событий или времени. Например, традиционный процесс
поддержки принятия решений может выглядеть таким образом: руководитель идет к
специалисту информационного отдела и делится с ним своим вопросом. Затем
специалист информационного отдела строит запрос к оперативной системе, получает
электронный отчет, интерпретирует его и затем доводит его до сведения
руководящего персонала. Конечно, такая схема обеспечивает в какой-то мере
поддержку принятия решений, но она имеет крайне низкую эффективность и огромное
число недостатков. Ничтожное количество данных используется для поддержки
критически важных решений. Есть и другие проблемы. Подобный процесс очень
медленен, так как длителен сам процесс написания запросов и интерпретации
электронного отчета. Он занимает многие дни, в то время, когда руководителю
может быть необходимо принять решение прямо сейчас, немедленно. Если учесть,
что руководителя после получения отчета может заинтересовать другой вопрос
(скажем, уточняющий или требующий рассмотрения данных в другом разрезе), то
этот медленный цикл должен повториться, а поскольку процесс анализа данных
оперативных систем будет происходить итерационно, то времени тратится ещё
больше. Другая проблема – проблема различных областей деятельности специалиста
по информационным технологиям и руководителя, которые могут мыслить в разных
категориях и, как следствие, – не понимать друг друга. Тогда потребуются
дополнительные уточняющие итерации, а это снова время, которого всегда не
хватает. Ещё одной важной проблемой является сложность отчетов для понимания. У
руководителя нет времени выбирать интересующие цифры из отчёта, тем более что
их может оказаться слишком много (вспомним огромные многостраничные отчеты, в
которых реально используются несколько страниц, а остальные – на всякий
случай). Отметим также, что работа по интерпретации ложится чаще всего на
специалистов информационных отделов. То есть грамотный специалист отвлекается
на рутинную и малоэффективную работу по рисованию диаграмм и т.п., что,
естественно, не может благоприятно сказываться на его квалификации. Кроме того,
не является секретом присутствие в цепочке интерпретации благожелателей,
заинтересованных в преднамеренном искажении поступающей информации.
Вышеуказанные недостатки заставляют задуматься и об общей
эффективности оперативной системы, и о затратах, связанных с ее существованием,
так как оказывается, что затраты на создание оперативной системы не окупаются в
должной степени эффективностью ее работы.
В действительности проблемы эти не являются следствием низкого
качества оперативной системы или ее неудачной постройки. Корни проблем кроются
в фундаментальном отличии той оперативной деятельности, которая
автоматизируется оперативной системой, и деятельностью по разработке и принятию
решений. Отличие это состоит в том, что данные оперативных систем являются
просто записями о некоторых имевших место событиях, фактах, но никак не
информацией в общем смысле этого слова. Информация – то, что снижает
неопределенность в какой-либо области. И очень неплохо, если бы информация
снижала неопределенность в области подготовки решений. По поводу непригодности
для этой цели оперативных систем, построенных на РСУБД, в свое время высказался
небезызвестный E.F. Codd, человек, стоявший в 70-е годы у истоков технологий
систем управления реляционными БД: “Хотя системы управления реляционными БД
доступны для пользователей, они никогда не считались средством, дающим мощные
функции по синтезу, анализу и консолидации (функций, называемых многомерным
анализом данных)”. Речь идет именно о синтезе информации, о том, чтобы
превращать данные оперативных систем в информацию и даже в качественные оценки.
OLAP позволяет выполнять такое превращение.
В основе OLAP лежит идея многомерной модели данных.
Человеческое мышление многомерно по определению. Когда человек задает вопросы,
он налагает ограничения, тем самым формулируя вопросы во многих измерениях,
поэтому процесс анализа в многомерной модели весьма приближен к реальности
человеческого мышления. По измерениям в многомерной модели откладывают факторы,
влияющие на деятельность предприятия (например: время, продукты, отделения
компании, географию и т.п.). Таким образом получают гиперкуб (конечно, название
не очень удачно, поскольку под кубом обычно понимают фигуру с равными ребрами,
что, в данном случае, далеко не так), который затем наполняется показателями
деятельности предприятия (цены, продажи, план, прибыли, убытки и т.п.).
Наполнение это может вестись как реальными данными оперативных систем, так и
прогнозируемыми на основе исторических данных. Измерения гиперкуба могут носить
сложный характер, быть иерархическими, между ними могут быть установлены
отношения. В процессе анализа пользователь может менять точку зрения на данные
(так называемая операция смены логического взгляда), тем самым просматривая
данные в различных разрезах и разрешая конкретные задачи. Над кубами могут
выполняться различные операции, включая прогнозирование и условное планирование
(анализ типа “что, если”). Причем операции выполняются разом над кубами, т.е.
произведение, например, даст в результате произведение-гиперкуб, каждая ячейка
которого является произведением ячеек соответствующих гиперкубов-множителей.
Естественно, возможно выполнение операций над гиперкубами, имеющими различное
число измерений.
3. История
создания OLAP-технологии
Идея обработки данных на многомерных массивах не является
новой. Фактически она восходит к 1962 году, когда Ken Iverson опубликовал свою
книгу “Язык программирования” (“A Programming Language”, APL). Первая
практическая реализация APL состоялась в поздних шестидесятых компанией IBM.
APL – это очень изящный, математически определённый язык с многомерными
переменными и обрабатываемыми операциями. Он подразумевался как оригинальное
мощное средство по работе с многомерными преобразованиями по сравнению с
другими практическими языками программирования.
Однако идея долгое время не получала массового применения,
поскольку не пришло еще время графических интерфейсов, печатающих устройств
высокого качества, а отображение греческих символов требовало специальных
экранов, клавиатур и печатающих устройств. Позднее английские слова иногда
использовали для замены греческих операторов, однако борцы за чистоту APL
пресекли попытки популяризации их любимого языка. APL также поглощал машинные
ресурсы. В те дни его использование требовало больших затрат. Программы очень
медленно выполнялись и, кроме того, сам их запуск обходился очень дорого.
Требовалось много памяти, по тем временам просто шокирующие объемы (около 6
МБ).
Однако досада от этих первоначальных ошибок не убила идею.
Она использовалась во многих деловых приложениях 70-х, 80-х годов. Многие из
этих приложений имели черты современных систем аналитической обработки. Так,
IBM разработала операционную систему для APL, названную VSPC, и некоторые люди
считали ее идеальной средой для персонального использования, пока электронные
таблицы не стали повсеместно распространены.
Но APL был слишком сложен в использовании, тем более что
каждый раз появлялись несоответствия между самим языком и оборудованием, на котором
делались попытки его реализации.
В 80-х годах APL стал доступен на персональных машинах, но
не нашел рыночного применения. Альтернативой было программирование многомерных приложений
с использованием массивов в других языках. Это было очень тяжелой задачей даже
для профессиональных программистов, что вынуждало ждать следующего поколения
многомерных программных продуктов.
В 1972 году несколько прикладных многомерных программных
продуктов, ранее использовавшихся в учебных целях, нашли коммерческое применение:
Express. Он в полностью переписанном виде остаётся и сейчас, однако
оригинальные концепции 70-х годов перестали быть актуальными. Сегодня, в 90-х,
Express является одной из наиболее популярных OLAP-технологий, и Oracle (r)
будет продвигать его и дополнять новыми возможностями.
Больше многомерных продуктов появилось в 80-х годах. В
начале десятилетия – продукт с названием Stratagem, позднее называемый Acumate
(сегодня владельцем является Kenan Technologies), который еще продвигался до
начала 90-х, но сегодня, в отличие от Express, практически не используется.
Comshare System W был многомерным продуктом другого стиля.
Представленный в 1981 году, он был первым, где предполагалась большая
ориентированность на конечного пользователя и на разработку финансовых
приложений. Он привнёс много концепций, которые, правда, не были хорошо
адаптированы, такие, как полностью непроцедурные правила, полноэкранный
просмотр и редактирование многомерных данных, автоматическое перевычисление и
пакетная интеграция с реляционными данными. Однако Comshare System W был
достаточно тяжел для аппаратного обеспечения того времени по сравнению с
другими продуктами и меньше использовался в будущем, продавался всё меньше, и в
продукте не делалось никаких улучшений. Хотя он и сегодня доступен на UNIX, он
не является клиент-серверным, что не способствует повышению его предложения на
рынке аналитических продуктов. В поздних 80-х Comshare выпустил продукт для
DOS, а позднее для Windows. Эти продукты назывались Commander Prism и
использовали те же концепции, что и System W.
Другой творческий продукт поздних 80-х назывался Metaphor.
Он предназначался для профессиональных маркетологов. Он также предложил много
новых концепций, которые только сегодня начинают широко использоваться:
клиент-серверные вычисления, использование многомерной модели на реляционных
данных, объектно-ориентированная разработка приложений. Однако стандартное
аппаратное обеспечение персональных машин тех дней не было способно работать с
Metaphor и поставщики вынуждены были разрабатывать собственные стандарты на
персональные машины и сети. Постепенно Metaphor стал работать удачно и на
серийных персональных машинах, однако продукт был выполнен исключительно для
OS/2 и имел свой собственный графический интерфейс пользователя.
Затем Metaphor заключил маркетинговый альянс с IBM, которой
впоследствии и был поглощён. В середине 1994 года IBM решила интегрировать
технологию Metaphor (переименованную в DIS) со своими будущими технологиями и
тем самым прекратить финансирование отдельного направления, однако заказчики
выразили своё неудовольствие и потребовали продолжить поддержку продукта.
Поддержка была продолжена для оставшихся заказчиков, а IBM перевыпустила
продукт под новым названием DIS, что, однако, не сделало его популярным. Но творческие,
новаторские концепции Metaphor не были забыты и видны сегодня во многих
продуктах.
В середине 80-х родился термин EIS (Executive Information
System – информационная система руководителя). Первым продуктом, ясно
продемонстрировавшим это направление, был Pilot’s Command Center. Это был
продукт, который позволял выполнять совместные вычисления, то, что мы называем
сегодня клиент-серверными вычислениями. Поскольку мощность персональных
компьютеров 80-х годов была ограничена, продукт был очень “сервероцентричен”,
однако этот принцип и сегодня очень популярен. Pilot недолго продавал Command
Center, но предложил много концепций, которые можно узнать в сегодняшних
OLAP-продуктах, включая автоматическую поддержку временных промежутков,
многомерные клиент-серверные вычисления и упрощённое управление процессом
анализа (мышь, чувствительные экраны и т.п.). Некоторые из этих концепций были
повторно применены позднее в Pilot Analysis Server.
В конце 80-х электронные таблицы были доминирующими на
рынке инструментов, предоставляющих анализ конечным пользователям. Первая
многомерная электронная таблица была представлена продуктом Compete. Он
продвигался на рынок как очень дорогой продукт для специалистов, но поставщики
не обеспечили возможность захвата рынка этим продуктом, и компания Computer
Associates приобрела права на него вместе с другими продуктами, включая
Supercalc и 20/20. Основным эффектом от приобретения CA Compete было резкое
снижение цены на него и снятие защиты от копирования, что, естественно, способствовало
его распространению. Однако он не был удачным. Compete положен в основу
Supercalc 5, но многомерный аспект его не продвигается. Старый Compete всё ещё
иногда используют в связи с тем, что в свое время в него были вложены немалые
средства.
Компания Lotus была следующей, кто попытался войти на рынок
многомерных электронных таблиц с продуктом Improv, который запускается на NeXT
машине. Это гарантировало, как минимум, что продажи 1-2-3 не снизятся, но когда
тот со временем был выпущен под Windows, Excel уже имел большую долю рынка, что
не позволило Lotus внести какие-либо изменения в распределение рынка. Lotus,
подобно CA с Compete, переместила Improv в нижнюю часть рынка, однако и это не
стало условием удачного продвижения на рынке, и новые разработки в этой области
не получили продолжения. Оказалось, что пользователи персональных компьютеров
предпочли электронные таблицы 1-2-3 и не интересуются новыми многомерными
возможностями, если они не полностью совместимы с их старыми таблицами. Так же
концепции маленьких, настольных электронных таблиц, предлагаемых как
персональные приложения, в действительности не оказались удобными и не
прижились в настоящем деловом мире. Microsoft (r) пошла по этому пути, добавив
PivotTables (в русской редакции это называется “сводные таблицы”) к Excel. Хотя
немногие пользователи Excel получили выгоду от использования этой возможности,
это, вероятно, единственный факт широкого использования в мире возможностей
многомерного анализа просто потому, что в мире очень много пользователей Excel.
4.
OLAP, ROLAP, MOLAP…
Общеизвестно, что когда Кодд опубликовал в 1985 году свои
правила построения реляционных СУБД, они вызвали бурную реакцию и впоследствии
сильно отразились вообще на индустрии СУБД. Однако мало кто знает, что в 1993 году
Кодд опубликовал труд под названием “OLAP для пользователей-аналитиков: каким
он должен быть”. В нем он изложил основные концепции оперативной аналитической
обработки и определил 12 правил, которым должны удовлетворять продукты,
предоставляющие возможность выполнения оперативной аналитической обработки.
Вот эти правила (текст оригинала сохранен по возможности):
1. Концептуальное многомерное представление.
Пользователь-аналитик видит мир предприятия многомерным по своей природе.
Соответственно и OLAP-модель должна быть многомерной в своей основе.
Многомерная концептуальная схема или пользовательское представление облегчают
моделирование и анализ так же, впрочем, как и вычисления.
2. Прозрачность. Вне зависимости от того, является
OLAP-продукт частью средств пользователя или нет, этот факт должен быть
прозрачен для пользователя. Если OLAP предоставляется клиент-серверными
вычислениями, то этот факт также, по возможности, должен быть незаметен для
пользователя. OLAP должен предоставляться в контексте истинно открытой
архитектуры, позволяя пользователю, где бы он ни находился, связываться при
помощи аналитического инструмента с сервером. В дополнение прозрачность должна
достигаться и при взаимодействии аналитического инструмента с гомогенной и
гетерогенной средами БД.
3. Доступность. Пользователь-аналитик OLAP должен иметь
возможность выполнять анализ, базирующийся на общей концептуальной схеме,
содержащей данные всего предприятия в реляционной БД, также как и данные из
старых наследуемых БД, на общих методах доступа и на общей аналитической
модели. Это значит, что OLAP должен предоставлять свою собственную логическую
схему для доступа в гетерогенной среде БД и выполнять соответствующие
преобразования для предоставления данных пользователю. Более того, необходимо
заранее позаботиться о том, где и как, и какие типы физической организации
данных действительно будут использоваться. OLAP-система должна выполнять доступ
только к действительно требующимся данным, а не применять общий принцип
“кухонной воронки”, который влечет ненужный ввод.
4. Постоянная производительность при разработке отчетов.
Если число измерений или объем базы данных увеличиваются, пользователь-аналитик
не должен чувствовать какой-либо существенной деградации в производительности.
Постоянная производительность является критичной при поддержке для конечного
пользователя легкости в использовании и ограничения сложности OLAP. Если
пользователь-аналитик будет испытывать существенные различия в
производительности в соответствии с числом измерений, тогда он будет стремиться
компенсировать эти различия стратегией разработки, что вызовет представление
данных другими путями, но не теми, которыми действительно нужно представить
данные. Затраты времени на обход системы для компенсации ее неадекватности – это
не то, для чего аналитические продукты предназначены.
5. Клиент-серверная архитектура. Большинство данных,
которые сегодня требуется подвергать оперативной аналитической обработке,
содержатся на мэйнфреймах с доступом через ПК. Это означает, следовательно, что
OLAP-продукты должны быть способны работать в среде клиент-сервер. С этой точки
зрения является необходимым, чтобы серверный компонент аналитического
инструмента был существенно “интеллектуальным”, чтобы различные клиенты могли
присоединяться к серверу с минимальными затруднениями и интеграционным
программированием. “Интеллектуальный” сервер должен быть способен выполнять
отображение и консолидацию между несоответствующими логическими и физическими
схемами баз данных. Это обеспечит прозрачность и построение общей
концептуальной, логической и физической схемы.
6. Общая многомерность. Каждое измерение должно применяться
безотносительно своей структуры и операционных способностей. Дополнительные
операционные способности могут предоставляться выбранным измерениям, и,
поскольку измерения симметричны, отдельно взятая функция может быть
предоставлена любому измерению. Базовые структуры данных, формулы и форматы
отчетов не должны смещаться в сторону какого-либо измерения.
7. Динамическое управление разреженными матрицами.
Физическая схема OLAP-инструмента должна полностью адаптироваться к
специфической аналитической модели для оптимального управления разреженными
матрицами. Для любой взятой разреженной матрицы существует одна и только одна
оптимальная физическая схема. Эта схема предоставляет максимальную
эффективность по памяти и операбельность матрицы, если, конечно, весь набор
данных не помещается в памяти. Базовые физические данные OLAP-инструмента
должны конфигурироваться к любому подмножеству измерений, в любом порядке, для
практических операций с большими аналитическими моделями. Физические методы
доступа также должны динамически меняться и содержать различные типы
механизмов, таких как: непосредственные вычисления, B-деревья и производные,
хеширование, возможность комбинировать эти механизмы при необходимости.
Разреженность (измеряется в процентном отношении пустых ячеек ко всем
возможным) – это одна из характеристик распространения данных. Невозможность
регулировать разреженность может сделать эффективность операций недостижимой.
Если OLAP-инструмент не может контролировать и регулировать распространение
значений анализируемых данных, модель, претендующая на практичность,
базирующаяся на многих путях консолидации и измерениях, в действительности
может оказаться ненужной и безнадежной.
8. Многопользовательская поддержка. Часто несколько
пользователей-аналитиков испытывают потребность работать совместно с одной
аналитической моделью или создавать различные модели из единых данных.
Следовательно, OLAP-инструмент должен предоставлять возможности совместного
доступа (запроса и дополнения), целостности и безопасности.
9. Неограниченные перекрестные операции. Различные уровни
свертки и пути консолидации, вследствие их иерархической природы, представляют
зависимые отношения в OLAP-модели или приложении. Следовательно, сам инструмент
должен подразумевать соответствующие вычисления и не требовать от
пользователя-аналитика вновь определять эти вычисления и операции. Вычисления,
не следующие из этих наследуемых отношений, требуют определения различными
формулами в соответствии с некоторым применяющимся языком. Такой язык может
позволять вычисления и манипуляцию с данными любых размерностей и не
ограничивать отношения между ячейками данных, не обращать внимания на количество
общих атрибутов данных конкретных ячеек.
10. Интуитивная манипуляция данными. Переориентация путей
консолидации, детализация, укрупнение и другие манипуляции, регламентируемые
путями консолидации, должны применяться через отдельное воздействие на ячейки аналитической
модели, а также не должны требовать использования системы меню или иных
множественных действий с пользовательским интерфейсом. Взгляд
пользователя-аналитика на измерения, определенный в аналитической модели,
должен содержать всю необходимую информацию, чтобы выполнять вышеуказанные
действия.
11. Гибкие возможности получения отчетов. Анализ и
представление данных являются простыми, когда строки, столбцы и ячейки данных,
которые будут визуально сравниваться между собой, будут находиться вблизи друг
друга или по некоторой логической функции, имеющей место на предприятии.
Средства формирования отчетов должны представлять синтезируемые данные или
информацию, следующую из модели данных в ее любой возможной ориентации. Это
означает, что строки, столбцы или страницы должны показывать одновременно от 0
до N измерений, где N – число измерений всей аналитической модели. В дополнение
каждое измерение содержимого, показанное в одной записи, колонке или странице,
должно также быть способно показать любое подмножество элементов (значений),
содержащихся в измерении, в любом порядке.
12. Неограниченная размерность и число уровней агрегации.
Исследование о возможном числе необходимых измерений, требующихся в
аналитической модели, показало, что одновременно может использоваться до 19
измерений. Отсюда вытекает настоятельная рекомендация, чтобы аналитический
инструмент был способен предоставить хотя бы 15 измерений одновременно и
предпочтительно 20. Более того, каждое из общих измерений не должно быть
ограничено по числу определяемых пользователем-аналитиком уровней агрегации и
путей консолидации.
Фактически сегодня разработчики OLAP-продуктов следуют этим
правилам или, по крайней мере, стремятся им следовать. Эти правила можно
считать теоретическим базисом оперативной аналитической обработки, с ними
трудно спорить. Впоследствии было выведено множество следствий из 12 правил,
которые мы, однако, не будем приводить, дабы излишне не усложнять
повествование.
Остановимся несколько подробнее на том, как отличаются
OLAP-продукты по своей физической реализации.
Как уже отмечалось выше, в основе OLAP лежит идея обработки
данных на многомерных структурах. Когда мы говорим OLAP, мы подразумеваем, что
логически структура данных аналитического продукта многомерна. Другое дело, как
именно это реализовано. Различают два основных вида аналитической обработки, к
которым относят те или иные продукты.
MOLAP. Собственно многомерная (multidimensional) OLAP. В основе
продукта лежит нереляционная структура данных, обеспечивающая многомерное хранение,
обработку и представление данных. Соответственно и базы данных называют
многомерными. Продукты, относящиеся к этому классу, обычно имеют сервер
многомерных баз данных. Данные в процессе анализа выбираются исключительно из
многомерной структуры. Подобная структура является высокопроизводительной.
ROLAP. Реляционная (relational) OLAP. Как и подразумевается
названием, многомерная структура в таких инструментах реализуется реляционными
таблицами. А данные в процессе анализа, соответственно, выбираются из
реляционной базы данных аналитическим инструментом.
Недостатки и преимущества каждого подхода, в общем-то,
очевидны. Многомерная OLAP обеспечивает лучшую производительность, но структуры
нельзя использовать для обработки больших объемов данных, поскольку большая
размерность потребует больших аппаратных ресурсов, а вместе с тем разреженность
гиперкубов может быть очень высокой и, следовательно, использование аппаратных
мощностей не будет оправданным. Наоборот, реляционная OLAP обеспечивает
обработку на больших массивах хранимых данных, так как возможно обеспечение более
экономичного хранения, но, вместе с тем, значительно проигрывает в скорости
работы многомерной. Подобные рассуждения привели к выделению нового класса
аналитических инструментов – HOLAP. Это гибридная (hybrid) оперативная
аналитическая обработка. Инструменты этого класса позволяют сочетать оба
подхода – реляционного и многомерного. Доступ может вестись как к данным
многомерных баз, так и к данным реляционных.
Есть еще один достаточно экзотический вид оперативной
аналитической обработки – DOLAP. Это “настольный” (desktop) OLAP. Речь идет о
такой аналитической обработке, где гиперкубы малы, размерность их небольшая,
потребности скромны, и для такой аналитической обработки достаточно персональной
машины на рабочем столе.
Оперативная аналитическая обработка позволяет значительно
упростить и ускорить процесс подготовки и принятия решений руководящим
персоналом. Оперативная аналитическая обработка служит цели превращения данных
в информацию. Она принципиально отличается от традиционного процесса поддержки
принятия решений, основанного, чаще всего, на рассмотрении структурированных
отчетов. По аналогии, разница между структурированными отчетами и OLAP такая,
как между ездой по городу на трамвае и на личном автомобиле. Когда вы едете на
трамвае, он двигается по рельсам, что не позволяет хорошо рассмотреть
отдаленные здания и тем более приблизиться к ним. Наоборот, езда на личном
автомобиле дает полную свободу передвижения (естественно, следует соблюдать
ПДД). Можно подъехать к любому зданию и добраться до тех мест, где трамваи не
ходят.
Структурированные отчеты – это те рельсы, которые
сдерживают свободу в подготовке решений. OLAP – автомобиль для эффективного
движения по информационным магистралям.
5. Типовая
архитектура систем многомерного интеллектуального анализа
